Building a Real-Time User Analytics Platform for 1 Million Active Users Using Spring Boot, Kafka & PostgreSQL

Oliver Thomas is a passionate developer and tech writer. He crafts innovative solutions and shares insightful tech content with clarity and enthusiasm.
Client
A fast-growing digital product company with over 1 million active users, generating analytics events and interactions at extremely high volume thousands of requests per second.
They needed a scalable analytics backend capable of:
-
Real-time event ingestion
-
Large-volume processing
-
Fast querying
-
Low infrastructure cost
-
Always-on uptime
Their old architecture was unable to handle the load.
Project Overview
The goal was to build a fault-tolerant, highly scalable real-time analytics system capable of:
-
Tracking user behavior
-
Storing metrics
-
Generating dashboards
-
Powering recommendations
-
Real-time activity streams
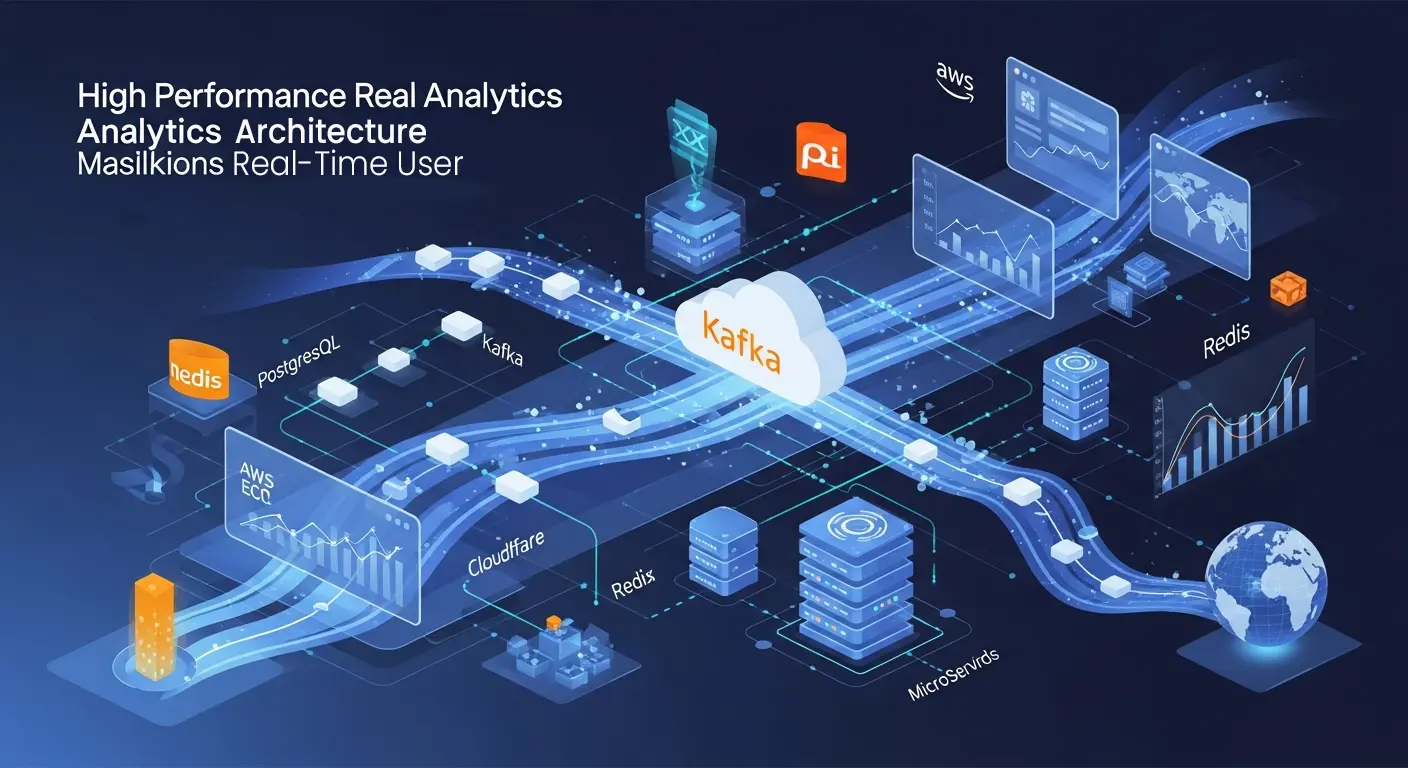
We built a high-performance analytics pipeline using:
Spring Boot 3.4.5 • JDK 17 • Kafka • Zookeeper • PostgreSQL • Redis Cache • Nginx • Tomcat • Cloudflare CDN • AWS EC2 autoscaling
Key Challenges
1. Extremely High Traffic
-
1M+ active users
-
Thousands of requests per second
-
Spikes during promotions or peak usage
2. Real-Time Requirements
Analytics must be processed:
-
Within milliseconds
-
With no message loss
-
Distributed horizontally
3. Database Overload
Postgres alone couldn’t handle raw event ingestion.
4. Message Ordering & Consistency
Analytics events needed guaranteed delivery and ordering.
5. Global User Base
Low latency required worldwide.
Our Solution
1. High-Performance Event Ingestion API (Spring Boot 3.4.5)
We created a non-blocking reactive API using:
-
Spring Boot 3.4.5
-
JDK 17
-
Spring WebFlux
-
Tomcat (as embedded server, tuned for high concurrency)
Optimizations included:
-
Connection pooling
-
Zero-copy request handling
-
Async processing
-
Automatic backpressure handling
The API could easily handle 10k+ requests/sec.
2. Kafka as the Real-Time Event Pipeline
We deployed a Kafka cluster backed by Zookeeper for:
-
High-throughput message ingestion
-
Partitioning for horizontal scalability
-
Guaranteed ordering per user/session
-
Replication & fault tolerance
Why Kafka?
Because it can handle millions of messages per second with low latency.
We used:
-
Topic sharding (user_id hashing)
-
Acks=all for durability
-
Retention policies for raw data
-
Stream filtering and enrichment
3. Real-Time Consumers & Processing Layer
We built analytics consumers using Spring Boot microservices:
-
Event parser
-
User activity aggregator
-
Real-time metrics generator
-
Storage writer services
Consumers were horizontally scalable:
-
Auto-scaling groups on EC2
-
Manual + metric-based scaling
-
Dedicated partitions
4. PostgreSQL for Processed Analytics Storage
Postgres used for:
-
Aggregated metrics
-
User insights
-
Reporting dashboards
Optimizations:
-
Partitioned tables
-
Read replicas
-
Index tuning
-
Connection pooling (HikariCP)
We also used Redis for:
-
Hot data
-
Caching analytics
-
Reducing Postgres load
5. Nginx + Cloudflare for Global Load Handling
To manage millions of global requests:
Cloudflare
-
Edge-level caching
-
WAF security
-
Bot filtering
-
Rate limiting
-
Low-latency routing
Nginx
-
Reverse proxy
-
Load balancing
-
SSL termination
-
Static asset caching
This reduced backend load by 30–50%.
6. AWS EC2 Auto Scaling
We deployed:
-
EC2 for microservices
-
Auto-scaling on CPU & Kafka queue depth
-
Dedicated Kafka nodes
-
Dedicated PostgreSQL instance
-
S3 for cold backups
-
CloudWatch for real-time metrics
7. Backup & Reliability Strategy
Kafka
-
Multi-broker replication
-
Automatic failover
Postgres
-
Daily snapshots
-
PITR (point-in-time recovery)
-
Multi-AZ replication
Application Services
-
Blue/Green deployments
-
Canary releases
-
Zero downtime upgrades
Architecture Diagram (Text Version)
Results / Impact
⚡ Real-Time Throughput: 10,000+ Requests/Second
System remained stable during heavy traffic spikes.
🧠 Accurate real-time analytics
Event processing delay: < 200 ms
🗃 Postgres load reduced by 60%
Thanks to:
-
Kafka buffering
-
Redis caching
-
Optimized write batching
🌍 Global low latency
Cloudflare delivered <80ms latency worldwide.
💰 Cost Efficient
Optimized resources and event processing reduced cloud bills.
🔒 Highly Reliable
Zero data loss with Kafka replication and Postgres backups.
🚀 Scalable Architecture
Easily supports growth from 1M → 5M active users.
Conclusion
By combining Spring Boot 3.4.5, Kafka, PostgreSQL, Nginx, Cloudflare, and AWS EC2, we built a high-performance, real-time user analytics platform capable of sustaining millions of users and thousands of requests per second all with stability, speed, and efficiency.
This architecture is modern, scalable, and future-proof for any fast-growing product.